Why do AI hallucinations occur — and how can enterprises prevent them in intranet answers?
AI hallucinations occur when intranet systems expose large language models to ungoverned, conflicting, or outdated content. Enterprises prevent them by constraining AI to governed sources with clear ownership, review cycles, and permission controls.
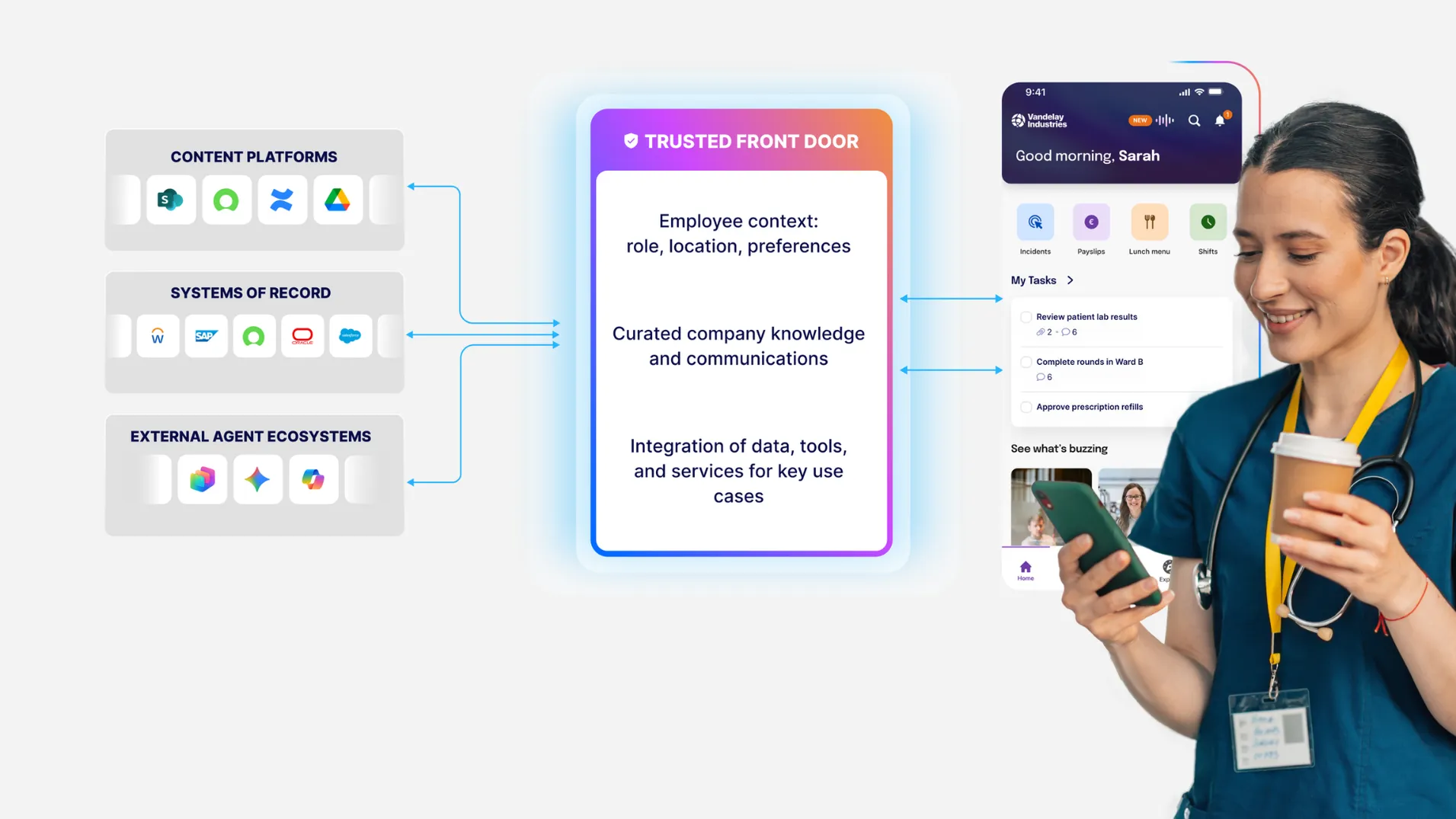

The short answer
AI hallucinations in enterprise intranets occur because models are forced to choose between conflicting, outdated, or unauthorized sources without a clear authority signal. The model does not invent randomly; it predicts the most probable answer based on the content it can access. When permissions, ownership, and review cycles are unclear, ambiguity forces the system to guess. Enterprises prevent hallucinations not by improving prompts alone, but by governing what enters the AI index in the first place. When AI is constrained to approved, permission-aligned content with enforced ownership and review controls, reliable answers become structurally possible.
What most organizations get wrong
Most organizations respond to AI hallucinations by adjusting prompts, switching models, or adding disclaimer language. This doesn't work because the problem isn't the model. It's the content environment the model operates in. If conflicting, outdated, or ungoverned sources remain in the index, a better prompt still produces an unreliable answer.
Why do AI hallucinations occur in intranet answers?
AI hallucinations in intranet environments are an authority failure. In most enterprises, overlapping drafts, outdated policies, regional variations, and informal guidance coexist without a clearly defined "official" version. Many pages lack a named owner, review cycle, or authoritative status marker. When the system provides no explicit authority signal, the model has no reliable way to prioritize one source over another.
AI does not create ambiguity. It exposes it. Prompting and low-temperature settings may stabilize phrasing, but they cannot resolve structural conflicts between sources. Accuracy improves only when ambiguity is removed at the source.
The bottom line: Hallucinations are a source problem, not a model problem. Fix the content environment first.
How do intranet permissions contribute to AI hallucinations?
Intranet AI hallucinations increase when access control does not align with authority. Most enterprise intranets rely on role-based access, region-based targeting, and inherited permissions across folders and systems. But access visibility is not the same as operational authority.
If AI retrieves from content a user technically has access to — but shouldn't rely on as official policy — hallucination risk increases. Common patterns include:
Draft visibility left unintentionally open
Archived content is still indexed
Region-specific policies exposed globally
Permission drift as roles change
Inherited access from legacy systems
From the model's perspective, accessible content is eligible content. This is also why relying on tools like Teams or Slack as a de facto knowledge base creates structural risk. Visibility in a channel does not equal governed authority.
Visible to user | Authority-validated | |
|---|---|---|
Approved policy | ✓ | ✓ |
Archived draft | ✓ | ✗ |
Regional variant | ✓ | ✗ |
Slack thread | ✓ | ✗ |
Why does more content make AI intranet answers less reliable?
AI intranet answers become less reliable as content volume increases without enforced authority. Large language models perform best when the context is narrow and internally consistent. As intranets expand without ownership controls, the answer space fragments and conflicting versions accumulate. This pattern is sometimes called context rot: the point at which expanding context reduces reliability instead of improving it.
The trade-off is structural: you gain completeness. You lose correctness.
Indexing more content increases coverage, but reduces accuracy unless governance defines which sources carry authority. Lean, validated knowledge bases consistently produce more reliable AI intranet answers than sprawling archives without control. The fix is not larger context windows. It is architectural restraint.
Why do AI hallucinations damage adoption?
AI hallucinations often erode trust immediately. Employees treat intranet answers as official guidance. When an HR, safety, or compliance answer is wrong, most users don't escalate it. They tend to disengage.
The operational cost compounds quickly:
Increased helpdesk tickets
Manual verification of AI answers
Slower decisions
Stalled AI adoption
McKinsey estimates employees already spend nearly two hours per day searching for information. If the intranet can't be trusted, that inefficiency multiplies rather than shrinks.
The bottom line: Trust is an adoption threshold, not a usability metric. In regulated environments, especially, hallucinations aren't minor defects; they're credibility failures.
How can enterprises prevent AI hallucinations in intranet answers?
Enterprises prevent AI hallucinations by building a layered control system. No single safeguard is enough, because each layer addresses a different failure mode.
Layer | What it does | What it can't do |
|---|---|---|
Configuration | Stabilizes behavior, reduces variability | Can't resolve source-of-truth conflicts |
Retrieval | Narrows the answer space to defined sources | Can't define which source is authoritative |
Governance | Defines authority before the model answers | Nothing; this is the decisive layer |
1. Configuration reduces variability, not ambiguity
Structured prompting and low-temperature settings make intranet AI more consistent, but they can't tell the model which internal document is the official truth.
Requiring citations, defining response boundaries, and explicitly allowing "I don't know" can reduce reasoning errors in controlled environments. Many enterprise deployments run at a lower temperature (often ~0.1–0.4) to reduce improvisation and make outputs more deterministic.
But configuration only changes how the AI responds, not what it should trust. If the model can access overlapping drafts, expired policies, or conflicting guidance, no prompt can reliably pick the authoritative version every time.
→ Configuration makes answers less random, but it does not resolve source-of-truth conflicts.
2. Retrieval narrows scope, but does not create authority
Retrieval-augmented generation (RAG) improves intranet AI reliability by forcing the model to generate answers from retrieved documents instead of relying on general training data. This significantly reduces open-ended invention.
The impact is measurable. A 2024 Stanford RegLab study found that general-purpose models hallucinated on legal queries between 58% and 82% of the time. Legal AI systems using retrieval reduced that substantially, but still produced incorrect responses in 17% to 34% of benchmark cases.
If the retrieval layer pulls outdated drafts or conflicting policies, the model will confidently summarize the wrong material. Without governance, retrieval simply makes guessing more efficient.
→ Retrieval reduces error, but it doesn't define authority.
3. Governance eliminates ambiguity at the source
Governance is the decisive layer because it defines authority before the model generates an answer. Without it, configuration and retrieval are simply more sophisticated ways of guessing. With it, the model no longer has to guess at all.
A separate 2024 Stanford study found that combining retrieval with guardrails reduced hallucinations by up to 96%. But guardrails only work when they're operationalized inside the system, not documented as policy in a slide deck.
For intranet AI, governance must be embedded directly into the publishing architecture:
Governance requirement | What it prevents |
|---|---|
Named owner per page | Orphaned, unaccountable content |
Automated review cycles | Outdated answers surfaced as current |
Enforced expiry dates | Expired policies remaining in the index |
Permissions aligned to identity systems | Unauthorized content retrieved |
Drafts excluded from AI indexing | Unapproved content treated as official |
When these controls live inside the intranet CMS and workflow (rather than layered on afterward), hallucinations become structurally unlikely instead of statistically reduced.
→ With Governance, AI stops predicting what sounds right and starts resolving what is approved.
TL;DR:
Configuration → stabilizes behavior
Retrieval → narrows the answer space
Governance → defines authority
What successful intranet governance looks like in practice
Successful intranet governance is visible when communication remains consistent under complexity and operational pressure.
Alaska Air Group offers a practical example. Operating in a highly regulated industry with thousands of frontline employees, the company needed a communication system that could maintain consistency across roles, regions, and operational conditions.
After teaming up with Staffbase:
Publishing responsibilities were clearly defined.
Local teams could share updates within structured boundaries, while central oversight ensured alignment and version control.
Ownership was visible. Distribution was targeted by role and location.
By defining ownership, version control, and role-based targeting, Alaska reduced ambiguity at the source.
The bottom line: Governance should be embedded into the intranet architecture.
Is your organization ready for intranet AI?
Intranet AI works when authority, access, and accountability are already defined. Before enabling AI, validate these three conditions:
Content has a named owner and review cycle
Permissions align with identity systems (SSO/RBAC)
Publishing boundaries prevent policy drift
If these aren't structurally enforced, AI will amplify ambiguity instead of reducing it.
How should stakeholders think about intranet AI readiness?
Different teams will raise different objections. Here's how to address the most common ones:
Stakeholder | Common objection | What actually solves it |
|---|---|---|
IT | "How do we control access and integrate safely?" | SSO and RBAC must govern both content visibility and retrieval logic. AI should inherit enterprise access rules, not bypass them. |
Communications | "Does decentralization break narrative consistency?" | Distributed publishing works when global ownership models, templates, and approval workflows prevent policy drift while allowing local relevance. |
HR | "How do we keep adoption from fading after launch?" | Usage declines after the first visible error. Reliability and visible ownership protect trust. Adoption is a governance outcome, not a launch campaign. |
Reliable intranet AI does not start with the model. It starts with operational discipline. The six steps below show how to structure authority before enabling AI.
 When not to use intranet AI
When not to use intranet AI
Not every environment is ready for AI, and deploying too early creates more risk than waiting. Three clear gates determine when to hold off:
Risk gate | Why it matters |
|---|---|
No named content owners | AI will surface outdated or conflicting guidance as if it were official |
High-stakes leadership communication | Layoffs, reorganizations, and values-driven messaging require human judgment, not AI summarization |
Broken or unaudited permissions | AI will either expose restricted content or return unverifiable answers |
The bottom line: AI is not a substitute for governance. It is a multiplier of it.
Next steps: Trust is an architectural decision
Trust in intranet AI is created by structure. AI should function as a librarian, not an author. It retrieves, summarizes, and connects information, but it doesn't decide what the company believes. Humans define policy, assign ownership, and stand behind the source of truth. AI makes that truth easier to access.
When governance is embedded into the communication architecture — across publishing workflows, identity systems, and distribution channels — AI operates within defined boundaries instead of guessing across ambiguity.
In enterprise environments, reliability is a system outcome. If you're evaluating employee AI for your intranet, start with architecture, not prompting.
Explore how governed employee AI works in practice

This article reflects the Staffbase POV and enterprise market conditions as of March 2026. Because AI capabilities and governance standards evolve rapidly, organizations should validate current technical requirements and compliance controls during vendor evaluation.
Frequently asked questions (FAQs)
Even with a clear architectural model, practical questions remain. How do you assess hallucination risk in measurable terms? Who owns governance — IT or Communications? And how long does it take to operationalize authority at scale? The following FAQs address the critical questions enterprises face when evaluating AI for their intranet.